
最近,诸多媒体报道了有关人工智能翻译已经可以达到人类译者水平的新闻,如:
The Verge
– Google's AI translation system is approaching human-level accuracy
The Verge
– 谷歌 AI 翻译系统的准确度趋近于人类
Quartz
– AI-based translation to soon reach human levels
Quartz
– 基于人工智能的翻译即将达到人类水平
ZDNet
– Microsoft researchers match human levels in translation news from Chinese to English
ZDNet
– 微软研究员表示,机器翻译中文新闻的水平可与人类匹敌
这一显著突破源于神经机器翻译(Neural Machine Translation, NMT)的出现,该方法使用神经网络来进行机器翻译。这项技术应用起来非常出色,是因为它有处理大规模翻译数据的能力。谷歌、Facebook 等大型科技公司在过去几年都引入了 NMT,并开发出了较高水平的翻译功能。
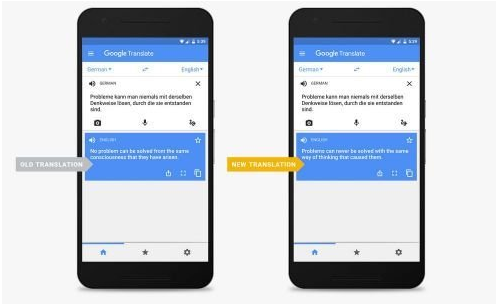
一个例子:引入 NMT 后,谷歌翻译的水平有明显提升
但 NMT 系统真的可以像上述题目说的那样,已经可以和人类译者相比了吗?还差得远呢。我们发现,目前的 NMT 系统并没有他们所说的那么好用,他们忽视了翻译中的许多关键问题。
▌ 什么是 NMT?
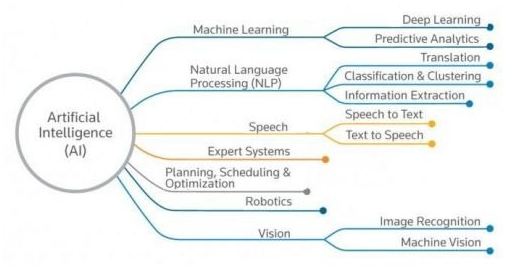
NMT 在整个 AI 领域中的位置
机器翻译(MT)是 AI 的一个分支,它致力于通过软件来进行不同语言之间的翻译。神经机器翻译(NMT)是一种较新颖的方法,它利用神经网络实现机器翻译。神经网络可以被训练,对数据进行模式识别,从而将输入数据转换为我们所需要的形式。接下来,我们看一个有关 NMT 系统的例子:
一个例子:将法语翻译成英语,引入 NMT 后质量有所提高
如果要将一句法语翻译成英语,NMT 的执行过程如下:先把需要翻译的法语句子输入网络,其中每个单词都会被编码成由数字组成的向量,这样网络才能对其进行处理。接下来,这些数字经过一系列数学公式的计算,最终生成一个新的数字序列,这个序列就代表了要输出的英文句子。
除了上述过程,在实际情况中,还有几个重要步骤:
在进行翻译前,人类工程师需要决定网络的具体结构;
工程师若要运行这样的网络,需要使用具备强大处理能力的计算机;
网络需要基于大量的语料数据,进行反复训练,才能具备合格的翻译水平;
最后,在测试 NMT 系统过程中,工程师要使用训练数据集中没有的语句进行测试,以确保系统在处理外部数据时也能正常工作。
▌ 强大的神经网络来源于强大的数据

引入海量数据后,深度神经网络的表现超过了其他模型
神经网络近期获得的成功源于大规模数据的出现。当有了足够多的数据作支撑,深度神经网络的提升尤为明显。同时,网络达到足够的深度,NMT 系统翻译的语句相比于过去技术翻译的结果也更为流畅。这里的“流畅”是指,输出的文本不会过于生硬,甚至有时候会被认为是人工翻译的结果。
▌ NMT 存在什么问题?
回想文章开头提到的几个题目 -- NMT 听起来极其卓越,但它真的可以与人工翻译相比吗?根本不可能。事实上,与人类相比 NMT 在很多方面都存在缺陷。
这些缺陷可归为三类:可靠性、记忆力和判断力。
可靠性:这可能是最令人担忧的一点,NMT 翻译并不可靠。NMT 系统无法保证准确度,常常出现漏掉否定词、整个单词甚至整个短语的情况。
记忆力:NMT 系统还有严重的短期记忆缺陷。目前,我们所建立的系统每次只能翻译一句话,导致其忽略了上文中可能包含的信息。
判断力:NMT 系统对外部的信息与知识几乎没有判断能力。对翻译工作来说,把握一段内容在特定语境中的理解是很重要的,但对机器来说这很难做到。
在接下来的内容里,我会阐述有关这三个缺陷的细节。
▌ 可靠性
NMT 无法检查其输出的信息是否真实。例如,NMT 系统可能漏掉否定词或整段信息。这些错误会导致什么后果呢?
“The US did not attack the EU! Nothing to fear,”
这是著名报纸 Le Monde 中用法语报道的内容,然后机器翻译成英语的结果是:
“The US attacked the EU! Fearless.”
试想象,如果这样错误的翻译遍布互联网,在假新闻病毒式传播之前我们来得及更正吗?令人沮丧的是,这样的灾难几乎无法挽回。
▌ 记忆力
当前的 NMT 系统还有一个明显的不足:每次只能单独翻译一个句子。这意味着机器并不知道它们当前翻译的句子之前的内容。而作为人类,我们阅读文章的时候会联系上下文。
那么为什么我们在训练 NMT 系统时,每次只用一个句子而不是整段文档呢?这里面有技术原因:首先,对神经系统来说,读取一段长文档,储存所有信息并快速调用都很困难;其次,当输入的信息量过大时,系统运行的时间也会更长。所以为了提高效率,我们在训练过程中都使用了单独的语句。
总之,不能联系上下文是 NMT 的主要问题,尤其对于翻译一个故事来说至关重要。讲故事是人类的行为,是创造力、智慧和表达的结合,也因此将我们与动物区分开来。如果 AI 翻译系统连有条理地翻译一个故事都做不到,更不用说文法上是否优雅,怎么能说它们达到了人类的水平呢?
▌ 判断力
假设你在读一篇关于音乐会的文章,然后使用 NMT 系统把英语翻译成法语,发给了你讲法语的朋友。在英文原文中,文章记录了对许多音乐会参与者的采访,其中包括一位年轻人的感慨:
“I’m a huge metal fan!”
但这句话被翻译成了:
“Je suis un énorme ventilateur en métal” (“I’m a large ventilator made of metal.”)
在这篇文章中,系统并不知道 "metal fan" 是指热爱金属音乐的一类人,直接翻译成了由金属制造的通风装置。

这个问题在机器发展初期就存在了,但至今无法解决。早在 1958 年的相关论文中就提到了该问题,这里有一个经典的例子:
The box was in the pen.
对此 NMT 系统会被 "pen" 这个单词困扰:它在这里指写字的工具还是围栏呢?
对 NMT 系统来说,关于世界的常识知识对翻译来说尤为重要。然而,对这些知识全部进行编码以及从大量数据中提取都是很困难的。我们需要一个有自主判断力的机制,并将常识知识引入到神经网络中。
▌ 什么是好的翻译?
我们应该如何评估机器翻译系统的水平?目前,最常用的方法是 BLEU score。我们把机器翻译出的内容与人工翻译的内容做对比,分别计算其 BLEU 分数。如果机器翻译结果中的单词和短语与人工的结果相似度很高,那么系统就会得到较高的 BLEU 分数。
BLEU score 是一种简单却有效的翻译评估方法,尤其在评估性能低的系统时。然而研究者发现,BLEU score 也经常与人类的观点不同。这意味着 BLEU 指标只能在若干低性能系统中挑选出最佳的一个,而面对性能更好的系统进行评估时比较吃力。
相比于 BLEU 评估方法,对翻译结果直接进行人工评估的方法更加出色,但也并非没有缺点。关于人工对机器翻译进行评估,存在两个不可忽视的问题:
人工评估不是自动的,所以成本较高且效率低。
人工评估往往会出现分歧。这个问题不仅存在于 BLEU 方法与人类之间,也存在于人类评估者之间。
总地来说,虽然人工评估效果更好,但它需要很高的成本,同时要求尽量不能出错。进一步来说,在将 NMT 系统与人类译者做对比时,要考虑到评估机制的限制因素。
▌ 我们仍在继续努力!未来会如何发展?
NMT 正在飞速发展,新的进步与突破也在被频繁报道着。新的研究正致力于解决以上提出的所有问题:可靠性、数据偏差、无意义输出、记忆力、对常识的判断力以及评估标准。
过去几年,NMT 在表现和效率方面都有所突破。这源于新系统不再需要连续处理数据,如按照从左到右或从右到左的顺序,从而使我们可以同时训练更多的数据,最后生成更合理的翻译结果。
同时,我们可以期待会有越来越多关于新研究的报道。哈佛的 OpenNMT: 一个可用于 LuaTorch、PyTorch 和 Tensorflow 的开源神经机器翻译工具包,正在迅速融入新的方法,以便于大家可以建立最好的翻译系统。由前谷歌研究员开发的新型商业系统 deepL,声称已经超越谷歌的翻译系统。这是一个发展迅速的领域,这也是一个见证 NMT 不断突破的时代。





